playbooks
Data Strategy
A suitable and flexible data management plan is essential for effective and trustworthy science. Our goals with this strategy is to maximize access, understanding, analysis speed, and provenance while reducing access barriers, unnecessary storage bloat, and cost.
1. Data perspectives
We think of data from three different perspectives:
-
Level
-
Origin
-
Flow
Each perspective requires different considerations for storage, access, and provenance management. Management practices for microscopy images are related to other data types, with some nuance.
Level
Your data level indicates the processing stage. For example, the lowest data level, or “raw” data, are the images acquired by the microscope. Technically, the biological substrate is the “rawest” data, but we consider the digitization of biological data to be the lowest level.
With biological data, there are many different kinds of intermediate data. Intermediate data are typically different sizes and thus have different storage requirements. Each intermediate data type requires unique considerations for access frequency, dissemination, and versioning.
Origin
Where your data come from also requires unique management policies. We use data originating from collaborators (both academic and industry) and data already in the public domain. Eventually, we will use data that we ourselves collect, but for the moment, we can ignore this origin category.
We need to consider access requirements and restrictions, particularly when using collaborator data. When storing restricted data, it is helpful to remember that all data will eventually be in the public domain.
Flow
Besides the most raw form, data are dynamic and pluripotent; always awaiting new and improved processing capabilities. We need to understand how each specific data level was processed at the specific moment in time (data provenance), and where each data level is ultimately heading for longer term storage. We also need capabilities to quickly reprocess these data with new approaches. Consider each data processing step as a new research project, waiting for improvement.
Flow also refers to users and data demand. We need to consider data analysis activity at each particular moment. For example, if the data are actively being worked on, multiple people should have immediate access. We need to align data access demand with storage solutions and computability.
2. Storage solutions
We consider the following categories of potential storage solutions for data:
-
Lab storage
-
Internal hard drive
-
External hard drive
-
-
Campus storage
- CU Anschutz - Dell PowerScale (Isilon)
- CU Boulder Research Computing - PetaLibrary
- CU Boulder Research Computing - High-performance Computing (HPC) Cluster Alpine
-
External storage
-
Image Data Resource (IDR)
-
Amazon S3 / Google Cloud Storage Buckets / Azure Blob Storage
-
Figshare / Figshare+
-
Zenodo
-
Github
-
Git Large File Storage (LFS)
-
Data Version Control (DVC)
-
OneDrive / Dropbox / Google drive
-
Each storage solution has trade-offs in terms of longevity, access, usage speed, version control, size restrictions, and cost (Table 1).
3. Microscopy Data Levels
From the raw microscopy image to the variable intermediate data types including single cell and bulk embeddings, each data level has unique data storage considerations (Figure 1).
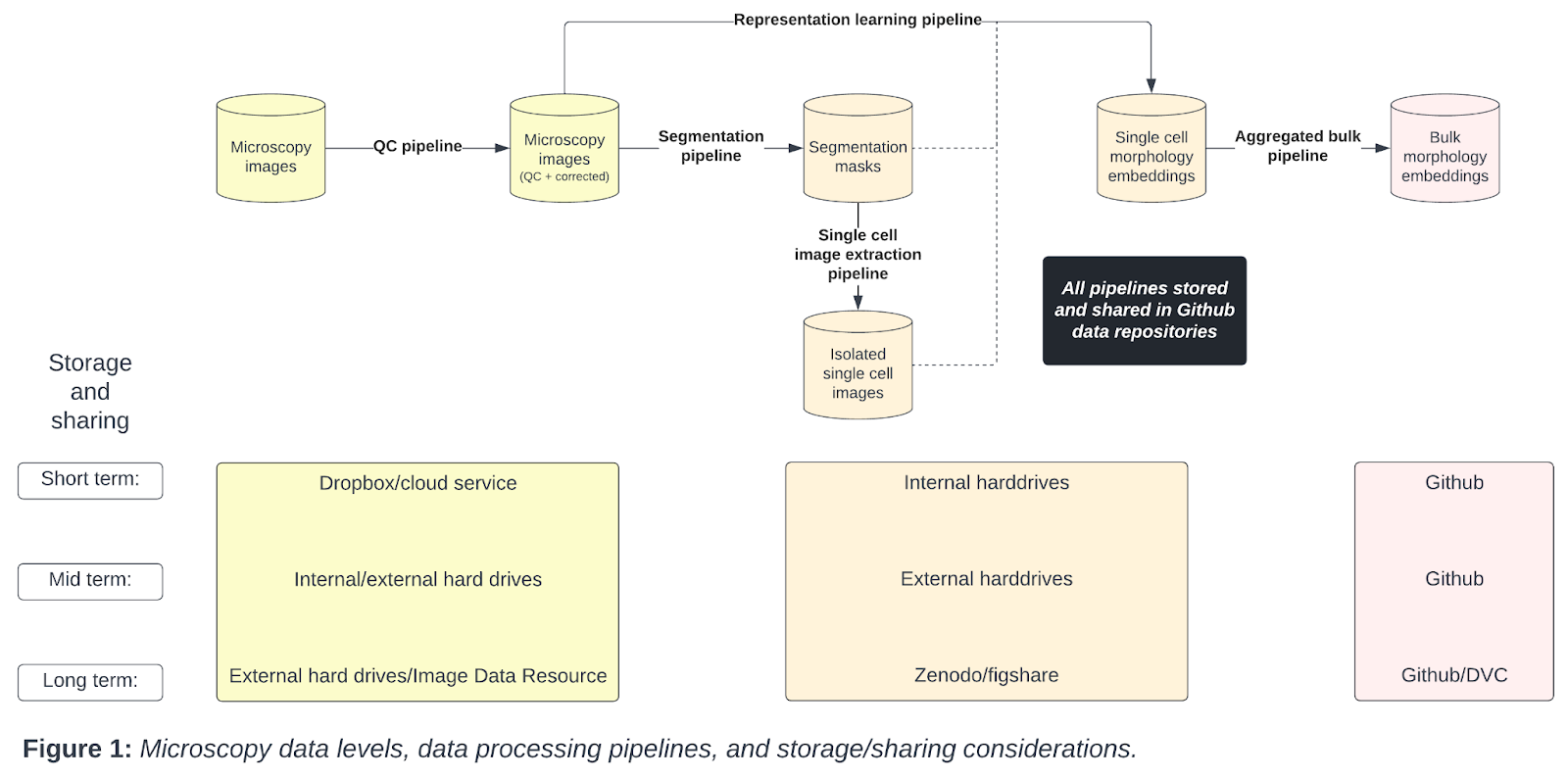
Starting with microscopy images, we apply a quality control (QC) pipeline to select and correct microscopy images for downstream analysis. Next, we apply segmentation pipelines to isolate individual single cells, which form segmentation masks. We have the option to apply a single cell image extraction pipeline to form a dataset of isolated single cell images. We apply representation learning pipelines to extract morphology features from some combination of the corrected microscopy image, segmentation mask, or isolated single cell images. Finally, we apply an aggregated bulk pipeline to turn the single cell morphology embeddings into aggregated bulk embeddings. Importantly, we have different short, mid, and long term storage and sharing solutions for each data type.
| Category | Solution | Longevity | Version Control | Access | Usage speed | Size limits | Cost | Notes |
|---|---|---|---|---|---|---|---|---|
| Lab storage | Internal hard drive | Intermediate | No | Private | Instant | <= 18TB (Total) | ~$15 per TB one time cost (Details) | |
| Lab storage | External hard drive | High | No | Private | Download | <= 18TB (Total) | ~$15 per TB one time cost (Details) | |
| Campus storage | CU Anschutz - Dell PowerScale (Isilon) | High | No | Private | Instant | Pay per use | $0.016 per GB per month | See rates here |
| Campus storage | CU Boulder Research Computing - PetaLibrary | High | No | Private | Instant | Purchased by Petabyte per year | $70/TB/yr (Active + Archive) | See rates here |
| Campus storage | CU Boulder Research Computing - HPC Cluster Alpine | Low | No | Private | Instant | /home/<username>: 2 GB, /projects/<username>: 250 GB, /scratch/alpine/<username>: 10 TB (see here for more information) |
Part of CU Anschutz agreement with CU Boulder | Note: scratch storage is periodically wiped on 90 day intervals. |
| External storage | IDR | High | Yes | Public | Download | >= 2TB (Per dataset) | Free | |
| External storage | Amazon S3 / Google Cloud Storage Buckets / Azure Blob Storage | Low | Yes | Public/Private | Instant | >= 2TB (Per dataset) | $0.02 - $0.04 per GB / Month ($40 to $80 per month per 2TB dataset) | |
| External storage | Figshare | High | Yes | Public | Download | 20GB (Total) | Free (Details) | |
| External storage | Figshare+ | High | Yes | Public | Download | 250GB > x > 5TB (Per dataset) | $745 > x > $11,860 one time cost (Details) | |
| External storage | Zenodo | High | Yes | Public | Download | >= 50GB (Per dataset) | Free (Details) | |
| External storage | Github | High | Yes | Public/Private | Instant | >= 100MB (Per file) (Details) | Free | |
| External storage | Git LFS (GitHub) | Intermediate | Yes | Public/Private | Instant | >= 2GB (up to 5GB for paid plans) | 50GB data pack for $5 per month (Details) | |
| External storage | DVC | Intermediate | Yes | Public/Private | Download | None | Cost of linked service (AWS/Azure/GC) | |
| External storage | OneDrive | Low | Yes | Private | Instant | >= 5TB (Total) | Free to AMC | |
| External storage | Dropbox | Low | Yes | Public/Private | Instant | >= 5TB (Total) | $12.50 per user / month (Details) | |
| External storage | Google Drive | Low | Yes | Public/Private | Instant | >= 5TB (Total) | $25 per month (Details) |
Table 1: Tradeoffs and considerations for data storage solutions.
4. Shared Data Storage Solutions
The lab uses tree-dwelling marsupial names for specific shared storage solutions except project-specific storage. When a new storage solution is acquired for use we suggest abiding this naming pattern.
| name | category | solution | suggested use | interface |
|---|---|---|---|---|
kinkajou |
Lab storage | External hard drive | Local storage for occasion where other campus or external storage solutions will not work well. | Filesystem mounts |
bandicoot |
Campus storage | CU Anschutz - Dell PowerScale (Isilon) | NAS-like storage solution for primary shared use within the lab. Can be mounted to local filesystems or use S3-like object storage API access. See demonstration repository for more information. | Filesystem mounts, rclone, S3-like object storage API’s(enabled at the request of CU Anschutz IT requests) |
koala |
Campus storage | CU Boulder Research Computing - PetaLibrary | Used for interacting with large amounts of data on CU Boulder Research Computing - HPC Cluster Alpine (bandicoot is not accessible from Alpine). |
Globus Connect Personal, filesystem mount (HPC Alpine) |
<project name>-bucket |
External storage | Google Cloud Storage Buckets | Used for receiving data from external collaborators. Reference gc-cloud-storage-bucket as a template or example. | gsutil, rclone, S3-like object storage API’s |
Table 2. Current storage solutions used by the lab along with their suggested use and interface.
Consider the following data flow in Figure 2 for projects to better understand how each of Table 2’s data solutions fit together.
flowchart LR
raw((Raw data)) --> |collaborator<br>transfer| bucket[Lab GCS<br>project bucket]
raw((Raw data)) --> collab_storage[Collaborator<br>storage solution]
computer["Lab member<br>computer"] --> |coordinates<br>use of| bandicoot
bucket --> |lab member<br>transfer| bandicoot["bandicoot<br>(Isilon)"]
collab_storage --> bandicoot
bandicoot --> |decide| decide_alpine{Needs<br>HPC Alpine?}
decide_alpine --> |if yes| koala["koala<br>(PetaLibrary)"]
computer -.-> globus["Globus<br>Personal Connect"]
globus -.-> koala
koala --> |eventually<br>transfer to| bandicoot
Figure 2. Raw data is received by the lab from Google Cloud Storage (GCS) project-specific buckets or a collaborator storage solution which is provided upfront. A lab member then transfers the data from the GCS bucket or collaborator storage solution to bandicoot (Isilon) so it may be used or shared within the lab. If the data need to be processed on HPC Alpine a lab member may decide to transfer the data to koala (PetaLibrary). Once HPC Alpine processing is complete the data are transferred back to bandicoot.
Using Isilon
Leveraging Isilon involves the use of a computer system with access to the campus or virtual private network (VPN). Isilon can be used through a filesystem mount or through the S3-like API. The S3-like API requires you to email IT support at: ucd-oit-helpdesk@cuanschutz.edu Mounting an Isilon directory entails using operating system tools to help handle authentication and persistence. Special note: the username provided when authenticating is your CU Anschutz enterprise username.
- MacOS:
mount_smbfsis shipped with MacOS automatically and can be used to setup a connection to Isilon directories. For example:mount_smbfs "$SHARE" "$MOUNT_POINT" - Linux:
cifs-utilscan be used in conjunction withmountto help setup a connection to Isilon directories. For example:mount -t cifs "$SHARE" "$MOUNT_POINT" -o username="$CIFS_USERNAME",domainautoNote:domainautois important for ensuring the connection to CU Anschutz shares.
Connection script
Please feel free to use the following script to automatically help setup your mount point to the Way Lab specific mount point on CU Anschutz Isilon: bandicoot.
curl https://raw.githubusercontent.com/WayScience/playbooks/refs/heads/main/internal/mount_bandicoot.sh | sh
Using PetaLibrary
Leveraging PetaLibrary on CU Boulder Research Computing’s HPC Cluster Alpine entails the use of sshfs to mount a PetaLibrary directory (e.g. koala) over an SSH connection to Alpine.
Alternatively, Globus Connect Personal can be used for transferring data to/from PetaLibrary without a filesystem mount (see koala in the table above).
Special note on $ALPINE_USERNAME: for CU Anschutz users, this will almost always take the form of an XSEDE-style identity: <your-rc-username>@xsede.org, rather than a plain CU Anschutz username.
Special note on IdentityFile=~/.ssh/alpine: this sshfs option tells SSH which private key file to use for authenticating to Alpine (here, a key named alpine stored in your local ~/.ssh directory). Replace this path with wherever you’ve stored the private SSH key you’ve set up for Alpine access; it does not need to be named alpine.
-
MacOS: install macFUSE and
sshfs:brew install --cask macfuseThen mount with
sshfs, for example:sshfs -o IdentityFile=~/.ssh/alpine \ "$ALPINE_USERNAME@login.rc.colorado.edu:/pl/active/$PETALIBRARY_DIR" \ "$MOUNT_POINT" -
Linux: install
sshfsthrough your distribution’s package manager, for example:# Debian / Ubuntu sudo apt install sshfs # Fedora / RHEL sudo dnf install fuse-sshfs # Alpine Linux sudo apk add sshfsThen mount using the same command form as above:
sshfs -o IdentityFile=~/.ssh/alpine \ "$ALPINE_USERNAME@login.rc.colorado.edu:/pl/active/$PETALIBRARY_DIR" \ "$MOUNT_POINT"
Note: speed comparisons between sshfs (PetaLibrary) and CIFS (Isilon) have not yet been performed; consider this if performance becomes a concern.